The re-evolution of the verification code: easy to read and useReturn
TELDAP e-Newsletter (June, 2012)
The re-evolution of the verification code: easy to read and use
Taiwan Digital Archives Expansion Project/CHIANG, Pei-Hang
(click:5290)
“Please enter the number in the image above.” For many people who have signed up for accounts on-line or left messages on websites, I believe this request is not strange to them. It oftentimes appears in the form of hard-to-identify graphics, text, arithmetic, etc. By the user entering the answer, it decides it is a human rather than some malicious bots using the computer.We termed such verification function as “Human-Computer identification code”, the full English term being Completely Automated Public Turning Test to Tell Computers and Humans Apart (CAPTCHA). We also often see it on webpages referred to as “the Verification Code”. However, average English-and-numbers verification codes are not convenient to use on the emerging mobile phone and other mobile devices for two limitations: 1) the number of different combinations is limited and therefore bear a higher risk of “brute force; 2) it requires typed input. Compared to traditional English-and-number human-computer identification code, Chinese CAPTCHA (CCAPTCHA) developed by Chen Ling-Chi, research associate at the Institute of Information Science, integrated the digital archive basis of “structure of Chinese characters database”. Using the method of dismantling Chinese characters into parts, he designed a way to click on the answer, allowing the evolved verification code a more friendly and easy to use interface.
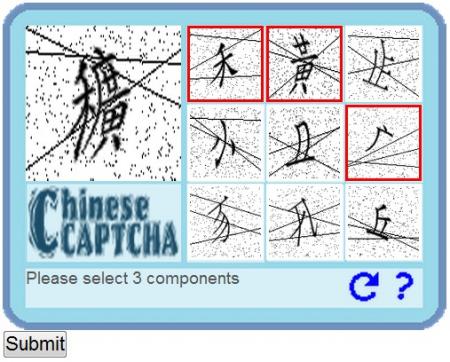
Easy to Read, Click the Character Parts Using the structure of Chinese characters, CCAPTCHA carries out dismantlement according to the structure of the characters. The system makes up questions by randomly choosing a character from the Chinese characters database and then dismantles it into parts. For example, the character穬 in the following figure will be dismantled into three recognizable parts, and then a few pars with the same strokes are selected for a multiple-choice question. The user can go to the next question if he cannot identify the first question. He can go on to the next step as soon as he provides the right answer.
The nine-grid square part selection is one of the features of CCAPTCHA. To allow people who don’t know Chinese to use the verification method, the users only need to select 3 appropriate parts for the character out of the nine options to complete the verification. The traditional CAPTCHA always require users to type in the letters in the images. In English and numbers, there are fewer alphabets and so we can directly enter input on the keypad. However, if Chinese characters are used, we will have a dilemma of not knowing how to type those characters. For the character穬, we can easily tell that it is made up of禾, 广, and黃. But if we were to type the input, we would have to know the pronunciation if using the phonetic input method. If using memorized character dismantlement rules like the Changjie method, we would need a certain amount of training. CCAPTCHA uses the click-to-select method, not only benefiting those that are not familiar with Chinese typing by allowing them to select answers based on the appearance of the characters, but also bringing convenience to users of mobile devices by sparing them from the pain of typing on a keypad. In addition, since the users can simply figure out the answer by looking at the characters, even the foreigners who do not have a clue about Chinese characters can use this method to answer verification questions.
Easy to Use – Not Afraid of Word Cracking Ordinary English-and-numbers verification can only uses 26 letters in upper and lower cases and Arabic numbers 0~9, for a total of 62 letters. The code X5TB in the following image, having only 4 letters, is at a high risk of the so-called brute force attack. The malicious programs can easily figure out the right code if they try out all possible letter combinations. Letters in simple images can also be identified using software. To make the verification code more reliable, some systems have added to the length of the codes or complexity like the one in the following image. But then the users would have to type in more letters and the exceedingly complicated image could create a hassle to the users.
Due to the breadth and depth of Chinese characters, if classified by strokes, there will be 206 parts with the four stroke alone in the structure of Chinese characters database. Since CCAPTCHA uses the dismantlement result of the tens of thousands characters in the database, there are almost a thousand of parts. Compared to the 62 letters in English and numbers, the complexity and variability of combination of Chinese character parts make CCAPTCHA the best tool to improve cracking difficulty.
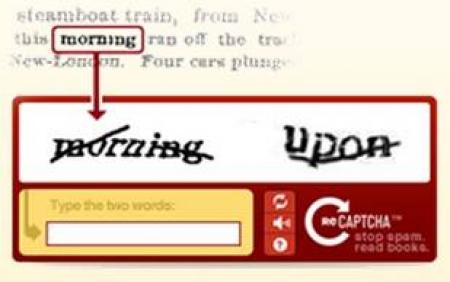
Fun, Become Buddies for Full-Text Establishment Besides the verification function, due to the need to input actions during log in, the audience can assist in document identification in reverse. We call this reCAPTCHA. In the process of verification, the system provides two sets of distorted characters at once for the user to enter. One of them is a character the system recognizes while the other is exerted from documents by the system and not yet identified. When the user are verified for log in, he must identify both sets of characters, on one hand for the purpose of verification and on the other for helping the digitization of the whole document. At present time, the English reCAPTCHA system has been developed quite mature. The reCAPTCHA system Google purchased has helped New York Times finished digitization of 20 years of scanned articles. Google also has plans to continue to finish up to 110 years of material.
Not letting foreign services shining alone, CCAPTCHA also started developing reCAPTCHA in hope of conducting large-scale digitization of Chinese documents in the future. For the time being, the accuracy of the reCAPTCHA system has reached above 80%. Therefore, besides providing the use of CCAPTCHA system for free to all sectors, the development team also expressed their hope to recruit digitization personnel from all sectors to provide Chinese image files and work on Chinese full-text establishment jointly. Moreover, the click-to-select parts action of CCAPTCHA was once tested as a game on Facebook during its development. People were invited to click to select the parts in the form of a game and were giving a rating according to their accuracy. Interestingly, when I was researching on the Internet, I saw Internet users showed great interest in this type of game and even posted recommending articles on blogs. It shows that in addition to its simple verification function, CCAPTCHA combined with full-text establishment, games, or educational concepts can lead to development of many different services.
Imagine one day, when we are logging in, taking Chinese characters test, or playing little games on Facebook, we are completing the textualization of important literature. At our fingertips, the images and texts of ancient literature have been organized neatly into full-text files. Not only the content of important literature is preserved, we also indirectly contributed to the circulation of digital content. It is nothing more than the best portrayal of the soft power of digital archive work. Before this happens, I would exhort all of you to keep in mind this easy to read and use, fun, and free verification system when you are carrying out digitization or building websites. Let us not only use the evolved verification code but also evolve the OCR full-text establishment system!
分享:
Publisher:Fan-Sen Wang, Vice President of Academia Sinica Editor-in-Chief:Zong-Kun Li Publishing Department:Taiwan e-Learning and Digital Archives Program, TELDAP Executive Editor:Sub-project: Digital Information - the New and Creative Way of Communicating Mailing Address:The Institute of History and Philology, Academia Sinica No.130, Sec. 2, Academia Rd., Nangang District, Taipei City 115, Taiwan TEL: (02) 27829555 ext:310 or 183 FAX: (02) 2786-8834 E-mail:newsletter@teldap.tw
Issue:TELDAP e-Newsletter (June, 2012) Publish Date:06/15 /2012 First Issue:02/15 /2007(Published on 15th every 2 months)
The copyright of all contents in this e-Newsletter belongs to TELDAP,Taiwan. The e-Newsletter publishing system is supported by the Core Platforms for Digital Contents Project for TELDAP.